


News Center
九章云极DataCanvas亮相中国城市商业银行信息化发展创新座谈会
2019.03.22

3月21日-22日,由《金融电子化杂志》主办的第十二届中国城市商业银行信息化发展创新座谈会在厦门隆重召开。本届大会以“融合 • 创新 • 共享”为主题,来自中国互联网金融协会、中国金融学会、中国科学技术大学等协会、高校的专家学者,和全国数百家城商行的科技部门主管领导齐聚一堂,共同探讨金融科技的前沿技术和创新实践。九章云极DataCanvas受邀出席此次盛会。
中国人民银行厦门市中心支行行长王彦青、厦门国际银行副总裁兼中国境内总经理黄大庆、城市商业银行资金清算中心主任陈晓平、中国金融电子化公司总经理及《金融电子化》杂志社社长张永福、中国互联网金融协会会长李东荣、中国人民银行科技司司长李伟等人出席现场并演讲致辞。

九章云极DataCanvas售前副总裁周晓凌受邀在本次座谈会上发表题为《新金融时代的数据科学应用价值》的精彩演讲。从数据科学发展进程,到数据建模落地痛点,再到数据科学平台的场景应用,周晓凌理论结合实践,通过实例生动展示出数据科学的应用价值和应用前景,获得与会嘉宾的好评和认可。

周晓凌说,在数据分析的发展过程中,以往强调的“洞见艺术”和“挖掘艺术”分别转变为标准化的科学组件和科学过程,数据科学这门独立的学科也就应运而生。不管是数据分析从艺术化到标准化的衍变,还是市场上流行的逻辑数据仓库(LDW),其目的都是通过提高已知数据分析效率,解决现有问题、预测未来结果。
机器学习平台建模, 直击建模效率痛点
以商业银行数据工程平台为例,数据在平台上需要经过数据源收集、采集整合、加工存储、分析计算、数据服务、模型服务等环节,其中模型服务环节的落地痛点尤为突出。传统的建模方式是由数据科学家结合业务知识和数据科学经验人为建模,甚至被称为“艺术”。
这种建模方式对建模者的知识要求和依赖性较高,同时由于建模过程中需运用多种数据加工方式、多种特征处理方式以及多种模型选用和模型训练,巨大的工作量导致建模时间很长,且结果不稳定,模型能力落地也就困难重重。
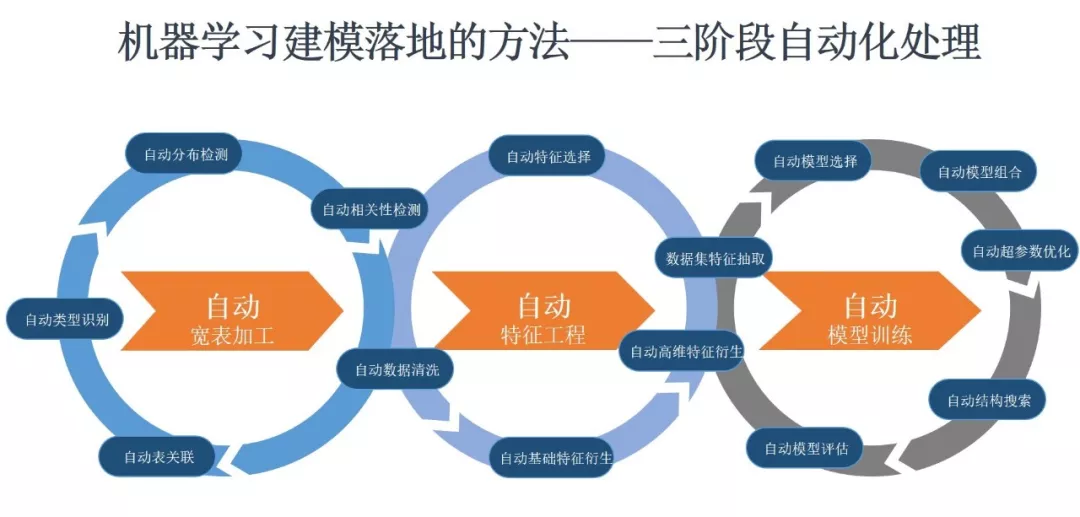
在DataCanvas数据科学平台上,通过将宽表加工、特征工程、模型训练三个阶段自动化处理,建模效率实现飞跃提升。宽表加工能够实现自动数据清洗、自动表关联、自动类型识别、自动分布检测和自动相关性检测;特征工程能够实现自动特征选择、数据集特征抽取、自动基础特征衍生和自动高维特征衍生;模型训练则能实现自动模型选择、自动模型组合、自动超参数优化、自动结构搜索和自动模型评估等。
“三位一体”、高可用、可解释,实现模型资产储备
除此之外,DataCanvas数据科学平台还具备“三位一体”建模功能。面向数据科学家的编码建模,面向IT工程师的拖拽式建模和面向业务人员的自动机器学习建模,三种建模方式在同一平台都可使用。不同知识背景的用户不仅可以在平台上择需选用建模方式,还可以与团队成员相互协作、加速建模。

由于DataCanvas数据科学平台的白盒算法和流程透明的特性,平台上输出的数据模型具备极强的可解释性和高可用性。可解释性,意为每条决策都能够被模型自动解释说明,让模型更易解读、更易理解;高可用性则意味着模型能够实际解决用户难题,能够投入到业务中使用。
在提高建模效率、降低建模成本的同时,数据模型也成为了可传承的模型资产,让银行实现模型能力积累。
基于场景的自动机器学习, 率先实现决策自动化
尽管宽表加工、特征工程、模型训练三个阶段实现了自动化处理,但将金融行业的庞杂数据全部自动化处理仍然是不可能完成的任务。为了加速模型落地、迅速提升银行业务市场竞争力,DataCanvas数据科学平台选择从业务场景出发,通过对某个场景的深入分析,定向实现此场景所需数据的宽表加工、特征工程和模型开发,直接加速此场景的模型落地。

自动机器学习建模成果,最终以决策形式服务于使用者,如在线产品推荐、客户流失预警、客户画像分析等。目前,DataCanvas已落地精准营销、信贷风控、流失预警、量化投研、智能运维、客户画像、运营优化等业务场景。
2019年,数据科学平台迎来了从小范围试点到大规模应用的市场节点。DataCanvas数据科学平台将发挥既有优势,继续深耕金融业务场景,为金融客户的业务提升带来更多价值,实力赋能金融企业AI建设,引领新金融时代!
- Try AIFS:AI Foudation Software & Services
- Hotline:+86 400-805-7188
- E-mail:contact@zetyun.com
- Join Us:hr@zetyun.com












