


News Center
免费体验100度算力包,极速部署不蒸馏满血版DeepSeek-R1!
发布日期:2025.02.10

1.背景介绍
DeepSeek-R1:你的智能新伙伴
DeepSeek-R1不仅仅是一个拥有6710亿参数的大模型,它更是一个在数学、编程和复杂推理任务中表现卓越的智能助手。无论是解决复杂的算法难题,还是编写高效的代码,DeepSeek-R1都能助你一臂之力,其性能已经可以与市面上那些顶级的闭源大模型平分秋色。
开启分布式推理的新时代
为了让每个团队和个人都能享受到DeepSeek-R1带来的无限可能,我们特别准备了一份详尽的最佳实践指南。通过使用vLLM和KubeRay这两款强大的工具,你可以轻松实现DeepSeek-R1的私有化部署。
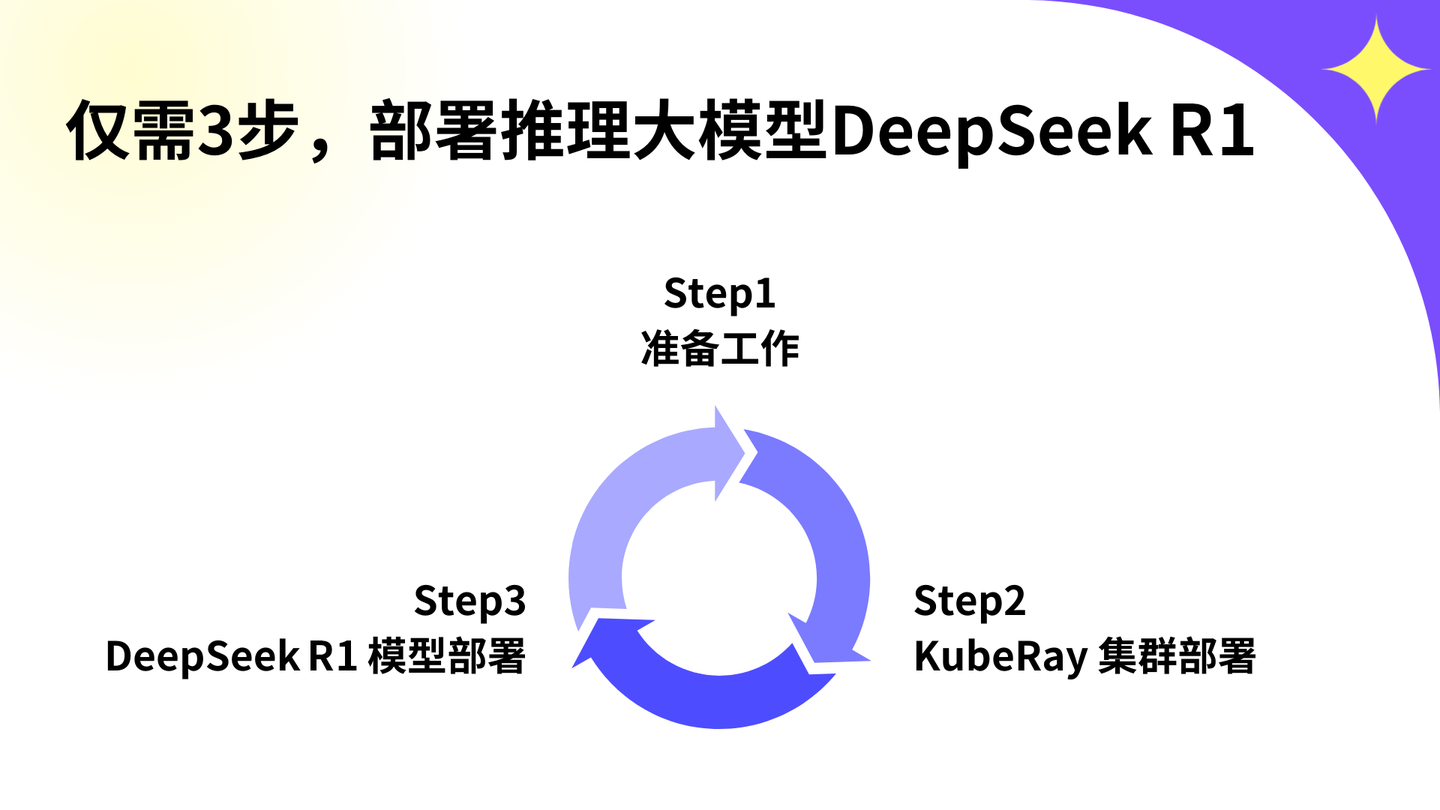
️ 三步实现你的专属AI部署
无论你是技术新手还是资深开发者,这份指南都将帮助你快速上手,只需三步,即可完成DeepSeek-R1的私有化部署。不要错过这个机会,立即行动起来吧!体验地址:
主要内容:
Step1 - 准备工作
1.账号开通
2.资源需求
3.开通弹性容器集群
4.配置文件准备
5.模型准备
Setp2 - KubeRay集群部署
1.安装KubeRay-Opertor
2.启动集群
3.安装访问配置
Setp3 - DeepSeek-R1部署
1.部署模型
2.访问模型
2.准备工作
本次部署会用到helm和Kubernetes,请先确保本地有可用的Kubernestes客户端工具kubectl,安装请参考文档。kubectl安装成功后,下载helm文件,按照如下方式进行安装:
Windows: 在环境变量 PATH 中设置helm文件所在的路径
Linux:将 helm 文件移动到目录 /usr/local/bin
在环境变量PATH中设置helm文件所在的路径
将 helm 文件移动到目录 /usr/local/bin
部署前需要先开通弹性容器集群,请跟随下面的步骤,完成前期准备工作。
2.1账号开通

点击“立即体验”进行账户开通注册
2.2资源需求
DeepSeek-R1模型的参数规模为6710亿,模型的文件大小约为642G。因此,在部署前,请确保开通的弹性容器集群的资源满足下表中的配置要求。
| 配置项 | 配置需求 |
|---|---|
| GPU | H800 * 16 |
| CPU | 128核 |
| 内存 | 512GB |
| 磁盘 | 1TB |
2.3开通弹性容器集群
请参考弹性容器集群的入门文档,完成集群的开通并了解基本的使用方法【了解更多】。成功后,得到kubeconfig文件、弹性容器集群的信息、对象存储和Harbor仓库的相关信息。
提示:
需要先设置环境变量,export KUBECONFIG=kubeconfig文件路径,才能够执行kubectl命令
2.4配置文件准备
为了方便操作,为大家准备了配套的配置文件及示例代码,请点击此处下载。
| 文件名 | 描述 |
|---|---|
| deepseek-secret.yaml | Harbor仓库的密钥,用于拉取镜像时的认证 |
| prepare.yaml | 准备工作的运行环境,不使用GPU资源,用于模型下载等工作 |
| kuberay-operator | KubeRay Operator的配置文件目录,用于启动operator |
| ray-cluster/ray-cluster.yaml | KubeRay集群的配置文件,用于启动KubeRay集群 |
| ray-cluster/ray-svcExporter-chat.yaml | 网络配置文件,用于暴露DeepSeek的推理服务端口,供外部访问 |
2.5模型准备
该模型文件较大,我们按照如下步骤,从模型市场中快速下载DeepSeek-R1模型文件。
创建Secret
首先,创建Secret用于拉取镜像时的验证。执行下面的命令,创建Secret资源。
# 创建namespacekubectl create namespace deepseek# 创建Secretkubectl apply -f deepseek-secret.yaml下载模型
执行kubectl apply -f prepare.yaml命令,创建准备环境Pod,用于下载模型。
Pod启动成功后,进入prepare的容器中,执行以下操作下载DeepSeek-R1模型。
# 进入prepare容器kubectl exec -it $( kubectl get pod -n deepseek | awk ' NR>1 {print $1}' | grep prepare ) bash -n deepseek # 安装huggingface工具pip install huggingface # 下载DeepSeek-R1模型huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1 --local-dir /model/deepseek-ai/DeepSeek-R1提示:
模型文件大约642G,下载时间较长,请耐心等待
3.KubeRay集群部署
本方案使用KubeRay做为分布式计算框架来实现多机多卡的分布式推理环境。
3.1安装KubeRay-Opertor
进入kuberay-operator目录,执行下面的命令,启动operator。
helm install kuberay-operator -n deepseek --version 1.2.2 .部署成功后,可以执行下面的命令操作已部署的资源。
# 查看相关资源
1.helm list -n deepseek
# 删除相关资源
2.helm uninstall kuberay-operator -n deepseek3.2启动集群
完成KubeRay-Opertor安装后,执行kubectl apply -f ray-cluster.yaml命令,启动KubeRay集群。
集群启动成功后,执行kubectl get pod -n deepseek查看服务运行情况。
3.3外部访问配置
在弹性容器集群中,无法直接使用NodePort方式暴露服务。对于需要外部访问的服务,我们可以使用ServiceExporter。ServiceExporter是弹性容器集群中用于将服务暴露到外部的组件,将其与需要对外提供服务的Service绑定,为用户提供外部访问的地址。
apiVersion: osm.datacanvas.com/v1alpha1
kind: ServiceExporter
metadata:
name: ray-svc-chat-exporter
namespace: deepseek
spec:
serviceName: raycluster-kuberay-head-svc
servicePort: 8000执行kubectl apply -f ray-svcExporter-chat.yaml命令,创建ServiceExporter资源。创建成功后,可以查看ServiceExporter的信息获取服务访问的地址。通过ServiceExporter方式暴露的服务端口均为22443
kubectl describe serviceExporter ray-svc-chat-exporter -n deepseek输出结果
信息省略···
Spec:
Service Name: raycluster-kuberay-head-svc
Service Port: 8000
Status:
Conditions:
Last Transition Time: 2025-01-05T13:04:48Z
Message: IngressRoute successfully updated, url: https://raycluster-kuberay-head-svc-x-deepseek-x-vcw2y2htee7r.sproxy.hd-01.alayanew.com
···提示:
当使用headless类型的svc时,只能暴露该svc上的一个端口。
4.DeepSeek-R1部署
4.1部署模型
KubeRay集群启动成功后,进入任意容器中,执行以下操作部署DeepSeek-R1模型。
1.kubectl exec -it $( kubectl get pod -n deepseek | awk ' NR>1 {print $1}' | grep kuberay-head ) bash -n deepseek
2.vllm serve /model/deepseek-ai/DeepSeek-R1 \ --tensor-parallel-size 16 \ --gpu-memory-utilization 0.95 \ --num-scheduler-steps 20 \ --max-model-len 8192 \ --trust-remote-code提示:
模型加载预计耗时40~50分钟,建议在tmux中执行模型部署命令。
4.2访问模型
from openai import OpenAIopenai_api_key = "EMPTY"openai_api_base = "https://raycluster-kuberay-head-svc-x-deepseek-x-vcw2y2htee7r.sproxy.hd-01.alayanew.com:22443/v1"client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,)chat_response = client.chat.completions.create(
model="/model/deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "讲个笑话."},
],
stream=True )输出结果:
嗯,用户让我讲个笑话。首先,我得确定他想要什么类型的笑话。是冷幽默、双关语,还是有情节的小故事笑话?不同的用户可能有不同的喜好。还要考虑是否适合所有年龄层,有没有可能冒犯到别人的内容。比如政治、宗教或者性别相关的笑话可能不太合适,所以最好避开这些敏感话题。
然后,我需要回忆一些经典的笑话结构,比如医生和病人的对话、动物笑话,或者日常生活中有趣的情境。医生和病人的笑话比较常见,容易引发共鸣,而且通常比较安全,不会有冒犯内容。比如那个经典的笑话:“医生,我放屁没声音但是很臭怎么办?”接下来需要想一个巧妙的回答,既出乎意料又带点幽默感。这里可以联想到声音和气味的关系,比如检查听力,这样既合理又搞笑。
另外,要注意笑话的长度不要太长,简短有力更容易让人记住和发笑。同时,检查语言是否口语化,有没有自然的笑点。避免使用复杂的词汇,保持轻松愉快的氛围。可能还要考虑笑话是否带有积极正面的情绪,让用户听了之后心情更好。
还要确保笑话的结构清晰,有铺垫和转折。比如,开头设置一个常见的情景,然后通过意想不到的转折制造笑料。比如病人描述问题,医生给出一个表面上不相关但逻辑上相关的建议,这种反差会产生幽默效果。
有没有可能这个笑话已经被广泛传播过了?用户可能听过类似的,所以需要稍微调整细节,增加新意。比如,把放屁的问题和听力检查结合起来,这样的组合比较少见,能带来新鲜感。另外,结尾的台词要干脆,留有余地让人回味,比如“您还是先检查一下听力吧!”,既点明了笑点,又不会拖沓。
最后,检查笑话是否符合文化差异,避免特定地区的梗或双关语。需要确保不同背景的人都能理解。比如提到的“放屁”是普遍现象,听力检查也是常见的医疗行为,所以跨文化传播不会有障碍。
总之,这个笑话应该简单易懂,安全无害,结构紧凑且有出人意料的转折,能够有效引发笑声。好的,我来分享一个轻松的小笑话:
医生对病人说:“以后尽量少吃宵夜。”
病人紧张地问:“是因为会消化不良吗?”
医生摇摇头:“不,主要是我每次半夜刷朋友圈,看见你发烤串火锅小龙虾的照片…真的很难专心值班。”
(希望这个小幽默能让你会心一笑~ )
5.总结
至此,我们完成了使用KubeRay和vLLM部署DeepSeek-R1模型的全部流程。本文为DeepSeek-R1私有化部署提供了从环境搭建到推理访问的完整技术路径。通过分布式推理模式,大尺寸模型的性能潜力得以充分释放,推动了 AI 应用的规模化落地。
咨询
- 售前咨询:AI基础软件产品&解决方案
- 联系电话:400-805-7188
- 联系邮箱:contact@zetyun.com
- 人才招聘:hr@zetyun.com












